GSoC 2017 : Integrating biodiversity data curation functionality
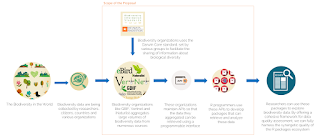
Any data used in data science analyses, either it be simple statistical inference-making or high end machine learnings, needs to meet certain qualities. Any dataset has 'Signal' the answer we are trying to find and 'Noise' the disturbances and anomalies in the data. The important part of preparing data for analysis is to make it easier to distinguish signal from noise. In biodiversity researches, data can be very huge. Thus there is a high probability of having a lot of noise. Giving researchers control to reduce this noise will provide a clean and tidy data. Biodiversity research is a huge spectrum. It varies from analyzing simple heredity, climate and Eco-system impacts on species to complex Genome Sequencing researches. So the requirements of data in each of these fields vary with the type of researches. Taxonomic researchers will be interested in taxonomic fields and not so in spatial or temporal aspects of the data. They will be okay with loosing spati...